-
Digital File Management
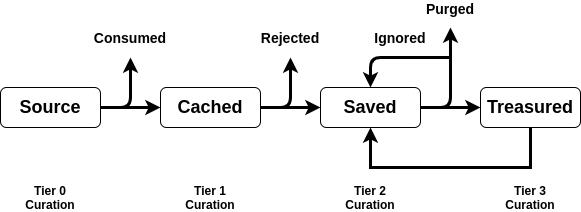
Been thinking about digital file management and came up with this model. It explains why a messy home folder is uncomfortable: it mixes up tier 1 and tier 2 curation.
Every digital file comes from a source. The source can be your web browser, your email client, your current terminal session, or your photoshop session. I am using file in the loosest possible sense. It is anything that has the potential to become a file, such as an html webpage.
Either it is immediately consumed or ignored or it is cached somewhere. For pdfs from a google search or an email attachment, the place it is cached is usually the downloads folder. In my experience, the downloads folder gets messy real fast because a lot of the cached files are rejected. You look at them once and then never again. It is an implicit rejection.
To move from tier 1 to tier 2, you need to save your file in some sort of basic structure. At the very least, you need to move it out of your cache into something that is not your cache. This is the problem with a cluttered home folder. If you add bajillions of temporary or test files or have many folders you did not create, then you are treating your home folder more like a cache than a place to save something.
The last category is what you treasure. These are the digital files that immediately come to mind when a certain topic comes up. It is anything in your working memory that has value to you. Not everything you save you’ll come back to. You may save it purely for the peace of mind of having a copy. In that case, you are pushing your cache more into your saved files. And eventually, you’ll do a spring cleaning. But given finite human resources, only a select few files, perhaps only the ones you are immediately working on, will be worth something.
I’ll admit there is some slight overlap between these tiers, but I think the continuum is well ordered.
subscribe via RSS